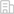|
中南大學(xué)
 搜 索
搜 索
搜 索
搜 索
全文相似性檢測(cè)系統(tǒng)是基于數(shù)據(jù)挖掘、自然語(yǔ)言處理、機(jī)器學(xué)習(xí)、概率統(tǒng)計(jì)等方法,以“特征提取、文本聚類(lèi)、相似性計(jì)算”為核心,在海量文檔集中快速、準(zhǔn)確、高效地發(fā)現(xiàn)相似的文檔及相似的內(nèi)容,檢測(cè)出項(xiàng)目申請(qǐng)書(shū)等材料的抄襲、多次申報(bào)和多頭申報(bào)等現(xiàn)象,在為項(xiàng)目的形式審查提供證據(jù)和決策支持,為科研誠(chéng)信提供有效的檢測(cè)手段。系統(tǒng)支持全文、圖像的相似性檢測(cè)以及引文甄別等功能。具體核心技術(shù)如下:
(1)高容錯(cuò),高性能的分布式項(xiàng)目全文檢索系統(tǒng)
基于科技專(zhuān)業(yè)詞庫(kù)、特征庫(kù)等、對(duì)項(xiàng)目全文建立索引,能夠?qū)?xiàng)目的標(biāo)題、作者、摘要、正文進(jìn)行模糊檢索、分類(lèi)搜索、高級(jí)復(fù)合搜索、全文檢索、圖片內(nèi)容檢索、跨庫(kù)檢索、多語(yǔ)言檢索、多格式文檔檢索、自定義時(shí)間檢索等。
實(shí)現(xiàn)分布式實(shí)時(shí)文件存儲(chǔ),并將每一個(gè)字段都編入索引,使其可以被搜索;同時(shí),支持不同粒度的多級(jí)字詞句索引和文檔索引。
實(shí)現(xiàn)在搜索結(jié)果集中,標(biāo)識(shí)關(guān)鍵詞,用特殊的字體及顏色和其他文字進(jìn)行區(qū)別,查詢(xún)者可在查詢(xún)結(jié)果片斷中一目了然的看到關(guān)鍵詞出現(xiàn)的位置。
支持一對(duì)一相似性檢測(cè)和一對(duì)多相似性檢測(cè)并生成檢測(cè)報(bào)告,支持報(bào)告模板格式可配置、支持檢測(cè)報(bào)告的批量導(dǎo)出。
(2)引文甄別
支持引文的作者、題名、其他題名信息[文獻(xiàn)類(lèi)型標(biāo)識(shí)/文獻(xiàn)載體標(biāo)識(shí)]、出版地、出版者、出版年、引文頁(yè)碼[引用日期]等主要實(shí)體信息甄別功能。
(3)圖像相似性檢查
支持從word、pdf格式的申請(qǐng)書(shū)中提取圖像,快速、準(zhǔn)確地檢索內(nèi)容相似的圖像,支持上傳單獨(dú)的圖像進(jìn)行檢測(cè),支持以項(xiàng)目書(shū)為單位進(jìn)行圖像檢測(cè),支持對(duì)檢測(cè)結(jié)果按各種條件的查詢(xún),支持相似圖像的證據(jù)溯源。
(4)相似性檢查服務(wù)接口
提供用戶認(rèn)證接口、提供相似性實(shí)時(shí)檢測(cè)API、檢測(cè)完成狀態(tài)獲取接口API、檢測(cè)報(bào)告生成和下載API、提供WEB界面,支持手動(dòng)實(shí)施臨時(shí)的檢測(cè)服務(wù)。
(5)系統(tǒng)快速準(zhǔn)確
系統(tǒng)支持word、txt和pdf格式的檢測(cè):實(shí)現(xiàn)pdf格式的提取成功率達(dá)到99.99%,pdf格式的章節(jié)劃分成功率達(dá)到99%,對(duì)word和txt指標(biāo)要求達(dá)到100%。提取速度達(dá)到每日30萬(wàn)篇。實(shí)現(xiàn)對(duì)百萬(wàn)級(jí)記錄數(shù)的搜索以及結(jié)合模糊搜索等查詢(xún)方式,將搜索時(shí)間壓縮到0.5秒以?xún)?nèi)。
(6)指標(biāo)可配置
實(shí)現(xiàn)項(xiàng)目相似性度量的自適應(yīng)閾值調(diào)整機(jī)制、動(dòng)態(tài)定義相似度指標(biāo)功能。
全文相似性檢測(cè)系統(tǒng)
在科研領(lǐng)域,每年都有大量的科研項(xiàng)目進(jìn)行各種申報(bào),這其中也不乏抄襲作假的行為,因此迫切需要一種能在海量文檔集中快速、準(zhǔn)確、高效地發(fā)現(xiàn)相似的文檔及相似的內(nèi)容,檢測(cè)出項(xiàng)目申請(qǐng)書(shū)等材料的抄襲、多次申報(bào)和多頭申報(bào)等現(xiàn)象的有力手段,確保科研誠(chéng)信及評(píng)審的公正公平。
高等院校作為創(chuàng)新人才的聚集地及原始性創(chuàng)新成果的重要源頭,是知識(shí)創(chuàng)新的主體,知識(shí)產(chǎn)出的主力軍,是產(chǎn)學(xué)研結(jié)合的重要組成部分。文章相似性檢測(cè)行業(yè)是一個(gè)新興的產(chǎn)業(yè)。伴隨著互聯(lián)網(wǎng)的崛起,以往高校學(xué)生在圖書(shū)館查閱資料的行為逐步轉(zhuǎn)移到網(wǎng)絡(luò)上,通過(guò)便捷的網(wǎng)絡(luò)進(jìn)行查閱相關(guān)的信息。正是因?yàn)樾畔⒉殚喌目旖荩@把“雙刃劍”同時(shí)也給在校的一部分學(xué)生提供了抄襲的便利,導(dǎo)致了更多高校抄襲事件、學(xué)術(shù)不端行為的高頻率發(fā)生。本成果可以廣泛應(yīng)用于高等院校、自然科學(xué)基金委、科技廳、專(zhuān)業(yè)學(xué)會(huì)等項(xiàng)目評(píng)審單位及大型科研機(jī)構(gòu),需要對(duì)項(xiàng)目申報(bào)材料進(jìn)行查重的單位。
產(chǎn)業(yè)化

掃碼關(guān)注,查看更多科技成果