




- 259 高校采購信息
- 691 科技成果項目
- 12 創新創業項目
- 0 高校項目需求
人工智能大模型的高性能加速系統


1. 痛點問題
大模型的發展已成為人工智能領域的一個重要趨勢,其具有更強的表達能力和更高的準確性,可以幫助人類解決更復雜的實際問題。然而,大模型的訓練面臨巨大的計算壓力。主流的大模型參數量已達到TB量級,必然需要使用分布式系統進行處理,通過將模型和數據分配到多個計算設備上進行并行計算,從而提高訓練速度。但是,分布式訓練的成本非常高昂,需要使用大量高性能的計算設備,而這些設備的價格居高不下,甚至在市場上難以獲得。
并行訓練系統的性能優化是降低訓練成本的重要手段。目前開源的分布式訓練軟件包括英偉達公司的 Megatron-LM和微軟公司的 DeepSpeed 等。雖然這些框架可以在給定的硬件平臺上對給定模型進行較好的并行訓練支持,但還存在一些局限性:
(1)性能仍有提升空間。目前廣泛使用的方案基于數據并行,通信量巨大,并行效率低下;
(2)依賴并行專家進行調優。現有系統提供了更多混合的并行方式的選擇,在數量眾多的可行的并行方案中選擇最優的并行方案是十分困難的,而任意選擇的并行方案可能會花費數倍于最優方案的時間;
(3)對于具有動態性的模型支持不足。現有的系統對于混合專家模型等具有動態負載特性的場景缺乏有效的處理機制,導致負載不均衡現象嚴重,從而導致訓練效率低下;
(4)缺乏對于多種不同硬件平臺的支持。目前主流的軟件系統與英偉達公司的GPU硬件綁定程度較深,難以移植到其它硬件平臺。
2. 解決方案
本技術成果包含以下核心技術點:(1)考慮硬件拓撲結構和性能特點的并行訓練軟件系統搭建與調優技術;(2)針對具有動態性的模型的高性能并行訓練系統;(3)向國產算力系統移植并行訓練系統的能力。
基于上述核心技術,本技術成果可支撐大模型并行訓練解決方案。為有大模型訓練需求的客戶,如中小型企業、科研院校,提供高效的大模型并行訓練資源。從超算中心、數據中心、云廠商等處獲取大規模計算資源,并根據客戶的需求部署效率最佳的并行訓練軟件系統,從而支持客戶進行高效的大規模大模型分布式訓練,降低大模型訓練成本。
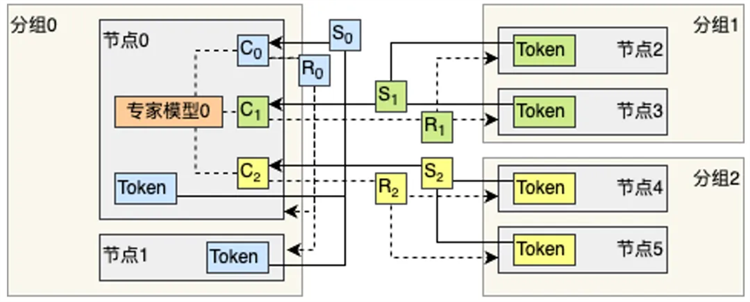
針對具有動態性的大模型的通信重疊調度機制
本項目擬先進行技術許可。
相比于已有的開源解決方案,本技術成果可提供針對不同硬件環境、目標模型規模,提供定制化并行性能調優,從而比選擇默認并行配置獲得更高的并行效率。例如針對混合專家模型,調優后的系統可獲得超過十倍的效率提升,從而為客戶節省更多成本。相比于專門雇傭并行專業人士的人力成本,使用統一的并行訓練解決方案成本更低。

掃碼關注,查看更多科技成果