



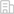

- 14 高校采購信息
- 11 科技成果項目
- 0 創新創業項目
- 0 高校項目需求
融合架構的高時效可擴展大數據分析平臺


研究背景:
大數據應用的多樣化
- 需要的計算模型、數據模型多樣化;
- 目前每類模型需要單獨的開源系統來支持(如HDFS、HBase、Neo4j、MongoDB,Flink,Spark,Tensorflow等)。
多系統導致大數據分析平臺非常復雜、效率低下。

研究目標:
研究和開發面向新型多計算模型融合架構的、高時效、可擴展的新 一代大數據分析支撐系統與工具平臺FAST(Fusion-Architecture, Scalable, Time-efficient big data analysis platform)。
針對目前大數據分析平臺復雜、效率低下的痛點,該系統具有三個 方面的優勢:首先,這套系統采用融合架構,一方面實現關系、圖、鍵 值、文檔等多種數據模型的高效融合,另一方面實現批處理計算、流計 算的深度融合,并可以通過SQL擴展語言來進行多模型的統一查詢,實現高效的跨模型查詢。其次,對于復雜系統來說,時效性非常重要,這 套系統采用融合架構提高效率是實現高時效的基礎,更重要的是,我們 對大數據分析從數據到用戶進行了端到端的全棧時效優化。最后,對于 大數據應用來說,系統擴展性非常重要,本系統在資源層、存儲層和計 算層進行了全面的擴展性優化。下面在融合架構、高時效和可擴展這三 個方面,分別詳細介紹FAST系統的三個主要亮點。
融合架構
FAST系統的第一個亮點是融合架構,我們在技術方面的創新主要包 括多數據模型融合和多計算模型融合兩方面。
多數據模型融合:
設計和研發了多模型數據管理與查詢引擎,支持關系、圖、鍵值、 文檔等多種數據模型,實現了查詢解析、查詢優化、元數據管理、數據 分布等功能,將多種數據模型進行統一管理和深度融合。同時擴展了SQL語言,通過統一的查詢接口支持對關系、鍵值、圖、文檔等數據進行獨立訪問或者跨模型查詢。

經過試驗,多模型數據融合查詢,比Spark 2.3.4的查詢時間能平均減少70.7%。目前spark等現有系統還需要手工編程方式來實現跨模型查 詢,所以FAST系統在易用性上也表現良好,降低使用門檻,提高開發效率。
多計算模型融合:
在計算層實現了最常見的批處理計算和流計算深度融合,批流融合的核心方法是在系統內部實現批和流的統一表達,批是對有限數據集 的運算,流是對無限數據流的計算,我們設計了UCollection結構對批和 流數據進行統一表達,通過識別的bounded標志,來確定是批、流、或批流融合。有了統一表達,可以開展一系列融合優化來提升系統性能。 并且對上通過Unified API統一用戶的批、流接口,實現二者在編程范式上的統一表達。對于批流混合的計算,融合架構系統的查詢延遲比Flink 1.4.2能減少57%,吞吐量平均可以提升到6.72倍。

高時效
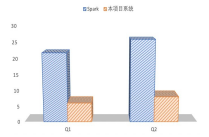
FAST系統的第二個亮點是高時效,即縮短大數據分析的時間消耗, 提高效率。由于大數據分析平臺是一個非常復雜的系統,為了做到高時效,系統不能存在性能短板,因此需要對大數據分析的整個過程進行端到端的全棧時效優化。如圖中所示,自下而上,需要在多模態存儲、批流融合、機器學習、人工操作各層都進行優化。
- 對于多模態存儲,面向應用負載和異構硬件特征進行自適應優化;
- 對于批流融合計算,在統一表達基礎上,進行系列融合優化技術, 包括DAG優化、迭代優化、部署優化、操作符優化等;
- 在機器學習層面,進行模型優化、消息優化、梯度優化、概率優化 等來提高時效;
- 而且我們也考慮到大數據分析過程中用戶人工操作的時效性問題, 通過智能地進行大數據分析方法和模型的推薦,來縮減人工操作的 時間。
可擴展
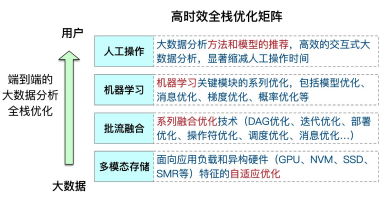
FAST系統的第三個亮點是可擴展,由于大數據應用規模很大,數據增速快,對系統可擴展性的要求非常高,為此我們在系統的資源層、 存儲層和計算層進行了全面的擴展性優化。
- 在資源層,系統都部署在云計算的虛擬化資源之上,利用了云計算資源的彈性機制進行系統擴展。并在系統中實現了可伸縮調整模塊, 能實時監控軟硬件系統的狀態,按照應用需求來自適應地進行彈性伸縮。
- 在存儲層,分布式存儲系統擴展性的關鍵在于分布式共識和一致性 協議(Raft),因此提出了KV-Raft、vRaft等進行Raft的擴展優化。
- 在計算層,我們擴展了機器學習模型的參數規模,使系統可以支持 到百億級別的超大規模機器學習模型訓練,并且性能方面有明顯提 升。
亮點成果:
融合架構大數據分析平臺目前已經在阿里巴巴雙十一進行示范應用。 從2020年11月10日至11月16日一周的時間,在阿里的生產環境中,研發 的系統一直連續穩定運行,基于淘寶和天貓的實際用戶信息進行大數據 分析,綜合運用了本系統的存儲、計算、機器學習等多個模塊的能力, 累計進行了184億件商品推薦。
同時在雙十一期間,基于智能交互向導技術,也面向電子商務應用 的賣家提供了“生意參謀”應用,基于大數據分析,幫助賣家分析產品 銷量變化的原因,以及促銷的有效手段等。

目前本項目研發的融合架構的高時效可擴展大數據分析平臺FAST 已經應用到阿里云的雙十一實時數據分析、騰訊的微信、QQ、騰訊視頻、廣點通、TDSQL 分布式數據庫,以及華為、小米、拼多多、Oppo、微眾銀行、人大金倉等企業中,可以顯著提升企業產品中大數據分析應用的工作效率,產生了很大的經濟社會效益,具有很大的推廣價值,能夠提升國內大數據分析系統和應用的國際競爭力,腿痛我國大數據產業的進一步發展。

掃碼關注,查看更多科技成果